|
This file is available on a Cryptome DVD offered by Cryptome. Donate $25 for a DVD of the Cryptome 10-year archives of 35,000 files from June 1996 to June 2006 (~3.5 GB). Click Paypal or mail check/MO made out to John Young, 251 West 89th Street, New York, NY 10024. Archives include all files of cryptome.org, cryptome2.org, jya.com, cartome.org, eyeball-series.org and iraq-kill-maim.org. Cryptome offers with the Cryptome DVD an INSCOM DVD of about 18,000 pages of counter-intelligence dossiers declassified by the US Army Information and Security Command, dating from 1945 to 1985. No additional contribution required -- $25 for both. The DVDs will be sent anywhere worldwide without extra cost. | |||
26 October 2006
| United States Patent | 7,127,392 |
| Smith | October 24, 2006 |
The present invention is a device for and method of detecting voice activity. First, the AM envelope of a segment of a signal of interest is determined. Next, the number of times the AM envelope crosses a user-definable threshold is determined. If there are no crossings, the segment is identified as non-speech. next, the number of points on the AM envelope within a user-definable range is determined. If there are less than a user-definable number of points within the range, the segment is identified as non-speech. Next, the mean, variance, and power ratio of the normalized spectral content of the AM envelope is found and compared to the same for known speech and non-speech. The segment is identified as being of the same type as the known speech or non-speech to which it most closely compares. These steps are repreated for each signal segment of interest.
| Inventors: | Smith; David C. (Columbia, MD) |
| Assignee: | The United States of America as represented
by the National
Security Agency (Washington, DC) N/A ( |
| Appl. No.: | 10/370,309 |
| Filed: | February 12, 2003 |
| Current U.S. Class: | 704/233 ; 704/208; 704/214; 704/215 |
| Current International Class: | G10L 15/20 (20060101) |
| Field of Search: | 704/214,204,210,213,215,216,219,217,500,233 |
| 5619565 | April 1997 | Cesaro et al. | |||
| 6023674 | February 2000 | Mekuria | |||
| 6182035 | January 2001 | Mekuria | |||
| 6249757 | June 2001 | Cason | |||
| 2002/0103636 | August 2002 | Tucker et al. | |||
| 2002/0147580 | October 2002 | Mekuria et al. | |||
D Smith et al., "A Multivariate Speech Activity Detector Based on the Syllable Rate", Proceedings of SPIE, vol. 3461, pp. 68-78, 1998. cited by other . D. Smith et al., "A Multivariate Speech Activity Detector Based on the Syllable Rate", Proceedings of ICASSP, vol. 1, pp. 73-76, 1999. cited by other. |
Primary Examiner: Dorvil; Richemond
Assistant Examiner: Vo; Huyen X.
Attorney, Agent or Firm:
|
FIG. 2 is a list of steps of the present invention.
 |
DETAILED DESCRIPTION
The present invention is a device for and method of detecting voice activity.
It is an improvement over the device and method disclosed in the two papers
of Smith et al. disclosed above.
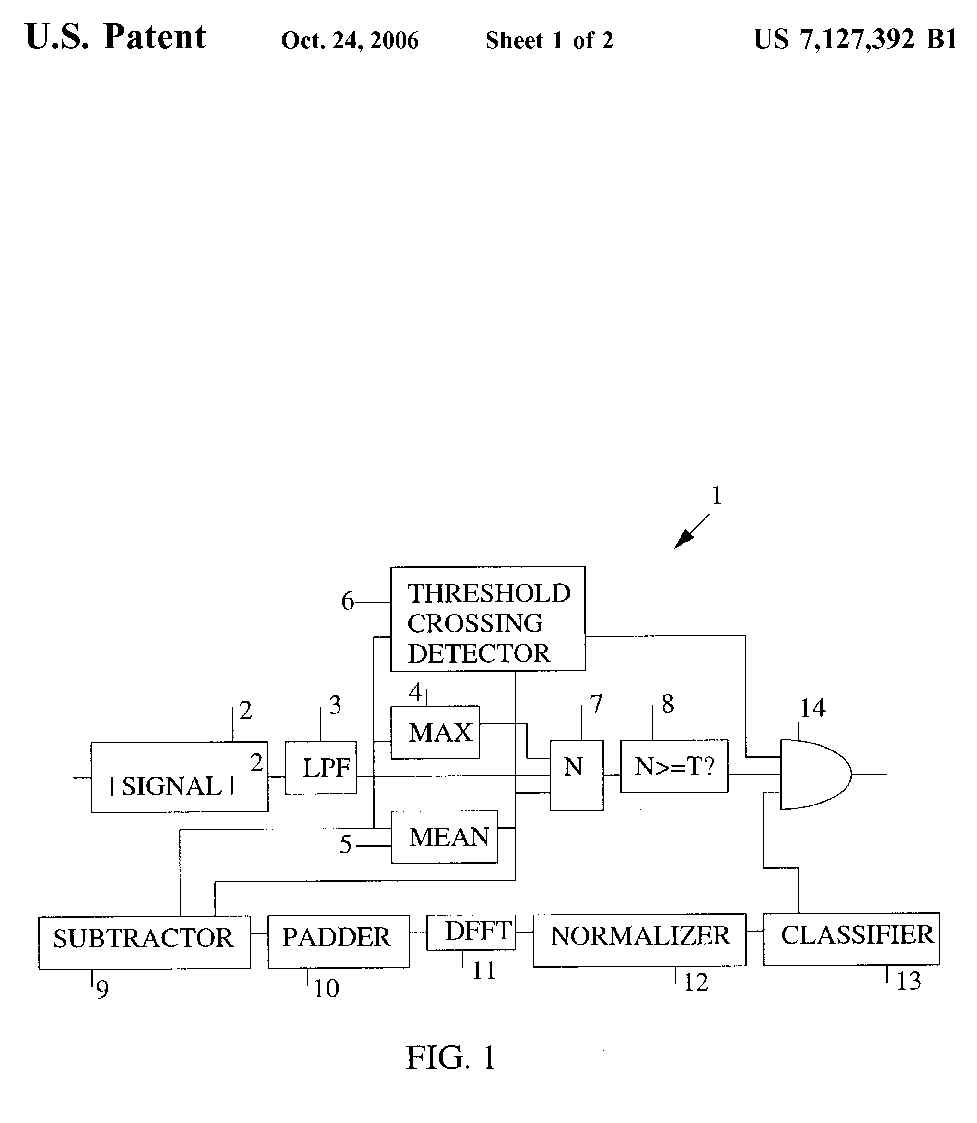
FIG. 1 is a schematic of the best mode and preferred embodiment of the present
invention. The voice activity detector 1 receives a segment of a signal,
computes feature vectors from the segment, and determines whether or not
the segment is speech or non-speech. In the preferred embodiment, the segment
is 0.5 seconds of a signal. In the preferred embodiment, the next segment
analyzed is a 0.1 second increment of the previous segment. That is, the
next segment includes the last 0.4 seconds of the first segment with an
additional 0.1 seconds of the signal. Other segment sizes and increment schemes
are possible and are intended to be included in the present invention. However,
a segment length of 0.5 seconds was empirically determined to give the best
balance between result accuracy and time window needed to resolve the syllable
rate of speech.
The voice activity detector 1 receives the segment at an absolute value squarer
2. The absolute value squarer 2 finds the absolute value of the segment and
then squares it. An arithmetic logic unit, a digital signal processor, or
a microprocessor may be used to realize the function of the absolute value
squarer 2.
The absolute value squarer 2 is connected to a low pass filter (LPF) 3. The
low pass filter 3 blocks high frequency components of the output of the absolute
value squarer 2 and passes low frequency components of the output of the
absolute value squarer 2. For speech purposes, low frequency is considered
to be less than or equal to 60 Hz since the syllable rate of speech is within
this range and, more particularly, within the range of 0 Hz to 10 Hz. The
low pass filter 3 removes unnecessary high frequency components and simplifies
subsequent computations. In the preferred embodiment, the low pass filter
3 is realized using a Hanning window. The output of the low pass filter 3
is often referred to as an Amplitude Modulated (AM) envelope of the original
signal. This is because the high frequency, or rapidly oscillating, components
have been removed, leaving only an AM envelope of the original segment.
The low pass filter 3 is connected to a first function block 4 for determining
the maximum value of the AM envelope (MAX), a second function block 5 for
determining the mean value of the AM envelope (MEAN), and a threshold-crossing
detector 6. An arithmetic logic unit, a digital signal processor, or a
microprocessor may be used to realize either of the first and second function
blocks 4,5.
The output of second function block 5 is connected to the threshold-crossing
detector 6. The threshold-crossing detector 6 counts the number of times
the AM envelope dips below a first user-definable threshold. In the preferred
embodiment, the first user-definable threshold is 0.25 times the mean of
the AM envelope. If the segment presented to the threshold-crossing detector
6 does not cross the first user-definable threshold then the segment is
identified as non-speech. However, just because the segment crosses the first
user-definable threshold does not mean that the segment is speech. Therefore,
processing of the segment continues if it crosses the first user-definable
threshold. The threshold-crossing detector 6 has an output for indicating
whether or the segment is non-speech. If the segment is non-speech then the
output of the threshold-crossing detector 6 is a logic zero. Otherwise, the
output of the threshold-crossing detector 6 is a logic one. A logic one output
does not necessarily indicate that the segment is speech. Additional processing
is required to make such a determination.
The outputs of the low-pass filter 3, the first function block 4, and the
second function block 5 are connected to a third function block 7 for determining
the number of points N on the AM envelope that lie within a user-definable
range. In the preferred embodiment, the user-definable range is from 0.25
times the mean of the AM envelope to MAX minus 0.25 times the mean of the
AM envelope. An arithmetic logic unit, a digital signal processor, or a
microprocessor may be used to realize the third function block 7.
The output of the third function block 7 is connected to a comparator 8 for
determining whether or not N is greater than or equal to a second user-definable
threshold. In the preferred embodiment the second user-definable threshold
is 10. The comparator 8 has an output for indicating whether the segment
is non-speech. If the number of points on the AM envelope within the
user-definable range is less than the second user-definable threshold then
the output of the comparators indicates that the signal segment is non-speech
(e.g., a logic zero). Otherwise, the output of the comparator 8 is a logic
one. A logic one output does not necessarily indicate that the segment is
speech. Additional processing is required to make such a determination.
The first function block 4, the second function block 5, the third function
block 7, and the comparator 8 represents the improvement over the device
and method described by Smith et al. in the two articles described above.
The improvement results in a speech activity detector that is more accurate
than the one disclose by Smith et al. above.
The outputs of the low-pass filter 3 and the second function block 5 are
connected to a subtractor 9. The subtractor 9 receives the AM envelope of
the segment and the mean of the AM envelope and subtracts the mean of the
AM envelope from the AM envelope. Mean subtraction improves the ability of
the voice activity detector 1 to discriminate between speech and certain
modem signals and tones. The subtractor 9 may be realized by an arithmetic
logic unit, a digital signal processor, or a microprocessor.
The subtractor 9 is connected to a padder 10. If the output of the subtractor
9 is not a power of two, the padder 10 pads the output of the subtractor
9 with zeros so that the result is a power of two. In the preferred embodiment,
eight bit values are used as a compromise between accuracy of resolving
frequencies and the desire to minimize computation complexity. The padder
10 may be realized with a storage register and a counter.
The padder 10 is connected to a Digital Fast Fourier Transformer (DFFT) 11.
The DFFT 11 performs a Digital Fast Fourier Transform on the output of the
padder 10 to obtain the spectral, or frequency, content of the AM envelope.
It is expected that there will be a peak in the magnitude of the speech signal
spectral components in the 0 10 Hz range, while the magnitude of the non-speech
signal spectral components in the same range will be small. The present invention
establishes a spectral difference between speech signal and non-speech signal
spectral components in the syllable rate range.
The DFFT 11 is connected to a normalizer 12. The normalizer 12 computes the
normalized vector of the magnitude of the DFFT of the AM envelope, computes
the mean of the normalized vector, computes the variance of the normalized
vector, and computes the power ratio of the normalized vector. A normalized
vector of a magnitude spectrum consists of the magnitude spectrum divided
by the sum of all of the components of the magnitude spectrum. The normalized
vector is a vector whose components are non-negative and sum to one. Therefore,
the normalized vector may be viewed as a probability density. The power ratio
of the normalized vector is found by first determining the average of the
components in the normalized vector and then dividing the largest component
in the normalized vector by this average. The result of the division is the
power ratio of the normalized vector. The mean, variance, and power ratio
of the normalized vector constitutes the feature vector of the segment received
by the voice activity detector 1. The normalizer 12 may be realized by an
arithmetic logic unit, a microprocessor, or a digital signal processor.
The normalizer 12 is connected to a classifier 13. The classifier 13 receives
the mean, variance, and power ratio of the segment computed by the normalizer
12 and compares it to precomputed models which represent the mean, variance,
and power ratio of known speech and non-speech segments. The classifier 13
declares the feature vector of the segment to be of the type (i.e., speech
or non-speech) of the precomputed model to which it matches most closely.
Various classification methods are known by those skilled in the art. In
the preferred embodiment, the classifier 13 performs the classification method
of Quadratic Discriminant Analysis. The classifier 13 may determine whether
the received segment is speech or non-speech based on the segment received
or the classifier 13 may retain a number of, preferably five, consecutive
0.5 second segments and use them as votes to determine whether the 0.1 second
interval common to these segments is speech or non-speech. Voting permits
a decision every 0.1 seconds after the first number of frames are processed
and improves decision accuracy. Therefore, voting is used in the preferred
embodiment. The classifier 13 may be realized with an arithmetic logic unit,
a microprocessor, or a digital signal processor.
The outputs of the classifier 13, the threshold-crossing detector 6, and
the comparator 8 are connected to decision logic block 14 for determining
whether the segment is speech or non-speech. In the preferred embodiment,
the decision logic block 14 is an AND gate. That is, the threshold-detector
6, the comparator 8, and the classifier 13 each put out a logic one value
to indicate speech and a logic zero value to indicate non-speech. So, a logic
one value from each of the threshold-crossing detector 6, the comparator
8, and the classifier 13 is required to indicate that the segment is speech.
However, a logic zero value from either the threshold-crossing detector 6,
the comparator 8, or the classifier 13 would indicate that the segment is
non-speech.
FIG. 2 is a list of steps of the method of the present invention.
The first step 21 of the method is receiving a signal.
The second step 22 of the method is extracting a user-definable segment from
the signal. In the preferred embodiment, the segment is 0.5 seconds in length.
A subsequent segment overlaps the most recent previous segment. In the preferred
embodiment, a subsequent segment overlaps the most recent previous segment
by 0.4 seconds so that the new part of the segment is only 0.1 seconds in
length. In an alternate embodiment, the signal segments processed are retained
as consecutive frames The frames (e.g., 5 frames) are then used as votes
to determine whether the 0.1 second interval common to the number of consecutive
0.5 second frames is speech or non-speech.
The third step 23 of the method is finding the absolute value of the signal
segment.
The fourth step 24 of the method is squaring the absolute value.
The fifth step 25 of the method is finding the Amplitude Modulation (AM)
envelope of the signal segment. In the preferred embodiment, the AM envelope
is found by low-pass filtering the segment.
The sixth step 26 of the method is finding the mean value of the/AM envelope.
The seventh step 27 of the method is finding the number of times the AM envelope
crosses a first user-definable threshold. In the preferred embodiment, the
first user-definable threshold is 0.25 times the mean of the AM envelope.
If the AM envelope doesn't cross the first user-definable threshold then
the eighth step 28 of the method is declaring the signal segment to be
non-speech, returning to the second step 22 if additional segments of the
signal are to be processed, and stopping if there are no other signal segments
to be processed. Otherwise, proceeding to the next step.
The ninth step 29 of the method is finding the maximum value (MAX) of the
AM envelope.
The tenth step 30 of the method is finding the number of points N on the
AM envelope within a user-definable range based on the mean and maximum values
of the AM envelope. In the preferred embodiment, the user-definable range
is from 0.25 times the mean value to MAX minus 0.25 times the mean value.
If N is less than a second user-definable threshold then the eleventh step
31 of the method is declaring the signal segment to be non-speech, returning
to the second step 22 if there are additional signal segments to be processed,
and stopping if there are no other signal segments to be processed. Otherwise,
proceeding to the next step. In the preferred embodiment, the second
user-definable threshold is 10.
The twelfth step 32 of the method is subtracting the mean value of the AM
envelope from the AM envelope.
If the result of the last step is not a power of two then the thirteenth
step 33 of the method is padding the result of the last step so that it is
a power of two. Otherwise, proceeding to the next step. In the preferred
embodiment, the result of the last step is padded with zeros if necessary.
The fourteenth step 34 of the method is finding the spectral content of the
AM envelope. In the preferred embodiment, spectral content is found by performing
a Digital Fast Fourier Transform (DFFT).
The fifteenth step 35 of the method is computing a normalized vector of the
magnitude of the spectral content of the AM envelope.
The sixteenth step 36 of the method is computing a mean, a variance, and
a power ratio of the normalized vector.
The seventeenth, and last, step 37 of the method is comparing the result
of the last step to empirically-determined models of mean, variance, and
power ratio of known speech and non-speech segments and declaring the signal
segment to be of the type of the empirically-determined model to which it
most closely compares. In the preferred embodiment, the seventeenth step
37 of the method is conducted by performing a Quadratic Discriminant Analysis